



By: Frederick Kang, CEO of Fox Tech; Sputnik Meng, Chief Scientist of Fox Tech
Proofread by Yanxi Lin, CTO of Fox Tech
Preface
In today’s digital age, with the rapid development of blockchain technology, people pay more and more attention to data privacy and security. In order to achieve more efficient and scalable blockchain applications, one of the solutions proposed is Zero-Knowledge Proof technology. Zero-knowledge proof, as a powerful cryptographic tool, can verify the authenticity of a statement without disclosing sensitive information.
In recent years, zkRollup, as one of the important innovations of blockchain capacity expansion technology, has attracted wide attention. zkRollup significantly improves blockchain throughput and scalability by packaging a large number of transactions, executing them off-chain, and using the zero-knowledge proof feature to verify the correctness of those transactions. In the implementation of zkRollup, how to distribute and package the transaction and generate the proof has become an important part of the zkRollup system.
In the Layer1 system, transactions are packaged in blocks and calculated by miners. In a Layer2 system, how a transaction is packaged, or how a Layer2 block is generated, is a separate consideration.
FOX is a project of Layer2 zkRollup expansion based on zkEVM. For this problem, FOX is exploring the use of pipeline processing mode to process transactions in batches, which is expected to greatly improve the efficiency.
This paper will discuss the application of pipelined zero-knowledge proof in zkRollup. First, we’ll look at the basic trade package. Then, we will focus on the pipeline method to generate zero-knowledge proof technology, and analyze its principle and application scenarios in detail.
The usual way to package deals
In traditional blockchain systems, the confirmation and packaging of transactions is a time-consuming and resource-intensive process. Typically, transactions are verified one by one and added to blocks, which are then agreed upon by consensus algorithms, allowing the state of the blockchain to be updated. However, this verification and packaging on a case-by-case basis has significant limitations, including low throughput and high latency.
In a conventional transaction packaging process, a batch of transactions, either user-submitted or from other chains, is first collected to be processed. These transactions are then validated to ensure their legality and validity. These validations include checking the signature of the transaction, verifying the validity and consistency of the transaction, and so on. Once the transactions are verified, they are packaged into a batch to form a block to be submitted.
While in the zkRollup system, the transactions submitted by users will also be first placed in the trading pool to wait. In the FOX system, Sequencer will capture the transactions in the trading pool regularly, execute and sort them locally, and form a trading package, that is, block. At this time, the trading execution results will be submitted to Layer1. This result, along with the transaction data, is also submitted to the Folder node that generates the proof.
According to our basic understanding of the zero-knowledge proof algorithm (readers can refer to FOX’s previous series of articles), Folder must obtain input and execution results if it wants to generate proof. This makes it necessary to wait for Sequencer to complete the execution of all transactions before handing over to Folder in a conventional way. In order to make more efficient use of computing resources, we hope to make Sequencer hand over to Folder for proof generation immediately after executing part of transactions.
The pipeline model that FOX is exploring
To achieve the above goal, we need to let Sequencer execute the transactions in batches and send the intermediate results to Folder immediately after executing a batch.
Specifically, assuming that the total number of package transactions is 100 and the number of individual batch transactions is 10, the pipeline processing can be represented by the following figure.
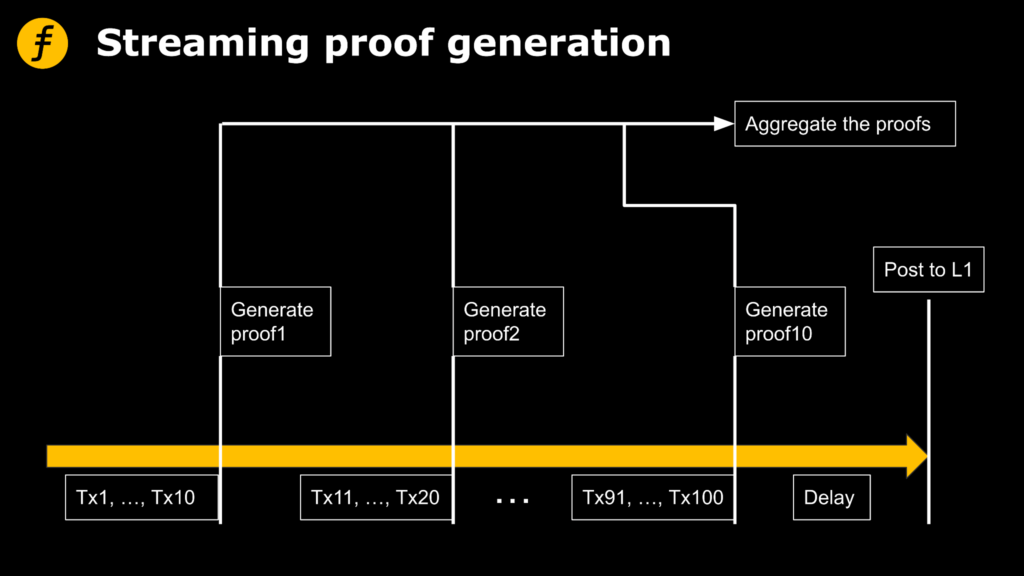
Let’s take a brief look at the time overhead of both approaches and discuss the situations in which pipelining is more efficient. For the sake of simplicity, the discussion here does not consider the time that Sequencer sends data to Folder.
Set the number of transactions in the transaction package as n, the number of batches as k, the execution time function of Sequencer as exe(), the generating time function of Folder as prove(), and the aggregated proving time function as aggr(). The total time of conventional mode and pipeline mode is Sum1 and Sum2.
Therefore, according to the above process, the conventional mode relies on Sequencer to execute first and then Folder for proof generation. The total time required is
Sum1 = exe(n) + prove(n)
However, the time of pipeline mode should include the execution time of Sequencer for the first batch of transactions, the time of generating proof later and the execution time of subsequent batches, as well as the final aggregation time.
Sum2 = exe(n/k) + max{k*prove(n/k),(k-1)*exe(n/k)} + aggr(k)
Therefore, by comparing the total duration of the two, the execution time function exe() can basically be approximated to a linear function, and for the prove(), the generation time of the prove algorithm of FOX system is proved to be a linear function, so the prove() is also a linear function.
It can be concluded that:
If exe(n)>prove(n), when the prove(n)>aggr(k), then Sum1>Sum2.
If exe(n)>prove(n), when (k-1)exe(n/k>aggr(k), then Sum1>Sum2.
Therefore, if the aggregation time aggr(k) is small enough and the proof generation time is a linear function, pipelining is very helpful to improve the system efficiency and reduce the total proof generation time.
The above analysis is only valid for the linear time proof algorithm, from which we can also see the importance of FOX’s adoption of linear time proof algorithm.
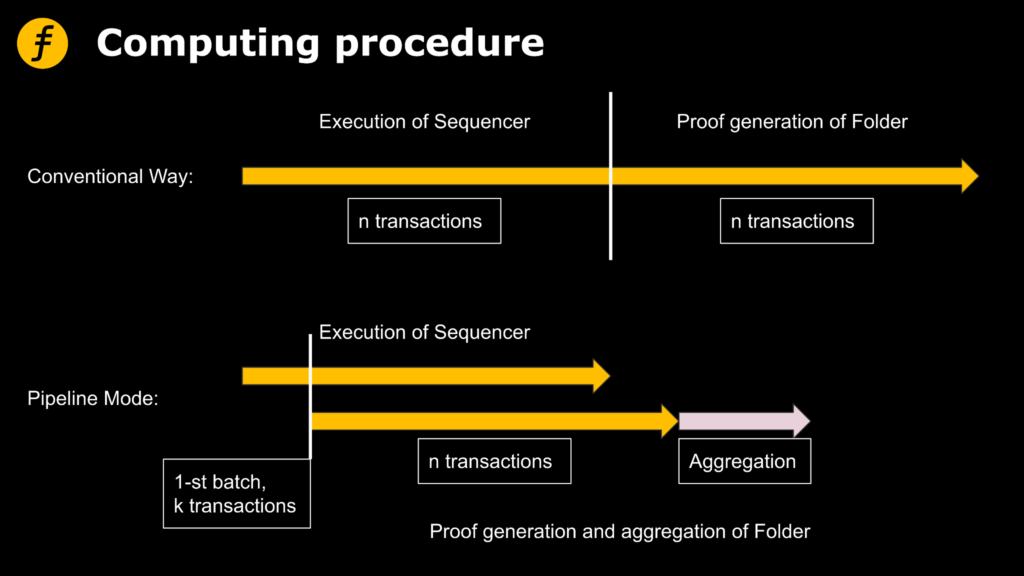
The reason why pipeline method is in the state of exploration is that through the analysis of this mode, it can be seen that the more batches each transaction package is divided into, the more data Sequencer needs to record and transfer to Folder and the higher the overhead is. However, for Folder, the calculation amount of a single processing will be reduced. The process of polymerization is more complicated. Therefore, how to segment it is a question that needs to be balanced, which also depends on the calculation performance of Sequencer and Folder.
Efficient allocation and packaging of transactions for batch generation proved to be a key optimization point
Efficiently allocating and packaging transactions and generating proofs are key optimization points in the zkRollup implementation.
FOX is constantly optimizing the model to find more efficient solutions. Here’s the basic process FOX uses:
- Trade collection: Collect transactions to be processed and store them in a trade pool. These may be user-submitted transactions, or transactions generated by other systems or contracts.
- Trade sort: Sorts the trades in the trade pool to determine the order in which they are packaged. Typically, you can use a sorting algorithm based on priority, timestamp, or other factors. The goal of sorting is to maximize the overall throughput and efficiency of the transaction.
- Transaction allocation: Assign sorted transactions to appropriate blocks. In zkRollup, a new block is usually created to hold a certain number of transactions. The allocation process can use greedy algorithms or other allocation strategies to maximize the capacity utilization of each block.
- Block packaging: The packaging of allocated transactions to form a complete block. In FOX’s Layer2 architecture, this block actually contains only the summary information of the transaction, which can be a hash or other compact representation of the transaction, rather than the details of the transaction, which are stored in the FOX Ringer for data availability (DA).
- Proof generation: Generate the corresponding proof for the packaged block. This proof should prove the validity of each transaction in the block and the consistency of the entire block. FOX’s pipeline mode is mainly applied to this link to make more efficient use of Folder computing power, and transfer the transactions in a block to Folder in batches for proof generation. Folder calculates the correctness of each batch of transactions respectively, and then aggregates them. Typically, this proof is based on FOAKS, a fast and targeted zero-knowledge proof algorithm that compares transactions in a block to state transition rules to verify that they follow the rules and constraints of the system.
- Proof verification: The recipient can use proof to verify the validity of a block without recalculating the entire block. This verification process can be highly efficient because it involves only the check of the proof without the need for complex calculations of the transaction.
FOX’s “pipeline mode” mainly occurs in the proof generation. In transaction collection and sorting, Sequencer collects the transactions to be processed, sorts them according to certain rules, and determines the order of execution. In subsequent trade batches, Sequencer executes the sorted trades in batches. A set of transactions from each batch is sent to the execution engine for processing. The execution engine simulates the execution of these transactions and records the intermediate results of state transitions. After each batch of transactions is executed, Sequencer sends the intermediate results to Folder.
This can be done by encoding intermediate results in the form of status updates, transaction hashes, and so on to the Folder’s communication channel wholesale. Folder After receiving intermediate results of each batch, these results are used to generate corresponding proofs batch by batch. These proofs are generated based on the FOAKS zero-knowledge proof algorithm developed by FOX, which uses intermediate results as input to prove the validity of the transaction and the consistency of the entire block.
The final step is proof verification. The resulting proof is sent to the Verifier, the smart contract Verifier deployed on Ethereum, to verify the validity of the block. The Verifier uses validation algorithms to check proofs to ensure their correctness and legitimacy.
Through this pipeline mode, Sequencer can continuously send intermediate results to Folder while executing transactions, so as to generate proofs batch by batch. This improves overall system efficiency and throughput while reducing latency in proof generation.
Conclusion
In zkRollup, this paper introduces a relatively novel scheme to generate proof for batch processing of transactions, pipeline mode, and analyzes the time cost of this mode in detail. For linear proof algorithm, reasonable use of pipeline mode can help reduce the total proof generation time. The proof system adopted by FOX realizes linear proof time, which is of great help to quickly generate proof and improve user experience. The FOX team will continue to explore and refine the solution.