



How temporal competition and long-tails skew block inclusion times.
by Tripoli
I asked a question during a Reddit AMA put on by the Ethereum Foundation earlier this week and one of the responses caught my eye:
I’m looking forward to seeing updated numbers for transaction inclusion times post-merge!
The theory says that average inclusion times should be ~2x lower, because the expected-time-to-next-block post-merge is now 6 seconds (as on average you’re halfway through a slot), whereas before it was 13 seconds. More regular inclusion times also reduce spikes. And in my personal experience, transaction inclusion these days is blazing fast, even compared to the post-1559 pre-merge era. It would be interesting to see what the data says.
Bitcoin block time dynamics are much more researched, and the data availability is higher. Therefore, I am going to transpose proof-of-work Ethereum over to Bitcoin for this analysis1. The two systems are very similar, with the major difference being that difficulty adjustments keep the average Bitcoin block time at 10 minutes, and kept the average Ethereum block time at about 13 seconds2.
However, block time averages are a giant simplification. The media often refers to Bitcoin miners as a bunch of computers solving complex mathematical problems, but that’s really not the case. Implicit from the word solving, the mainstream analogy suggests that mining rigs are constantly getting closer to the solution, but that’s not how mining works. The simplest analogy to hashing is flipping a coin and trying to get heads 77 times in a row3. Incorrect hashes do not provide meaningful progress, this is a version of the Gambler’s Fallacy—all hashes are independent, when a hash fails there is no progress.
The independence of attempts and the resulting lack of progress is described as memorylessness. Regardless of how long it has been since the last block, Bitcoin miners are constantly just as likely to discover the next block: the next block is always, on average, 10 minutes away.
If you’re interested in the quirks around Bitcoin block interval variance, Jameson Lopp wrote a great piece a couple of years ago. The TL;DR is that, ignoring edge cases stemming from very rapidly discovered blocks, block intervals follow a exponential probability distribution, of which memorylessness is a defining trait.
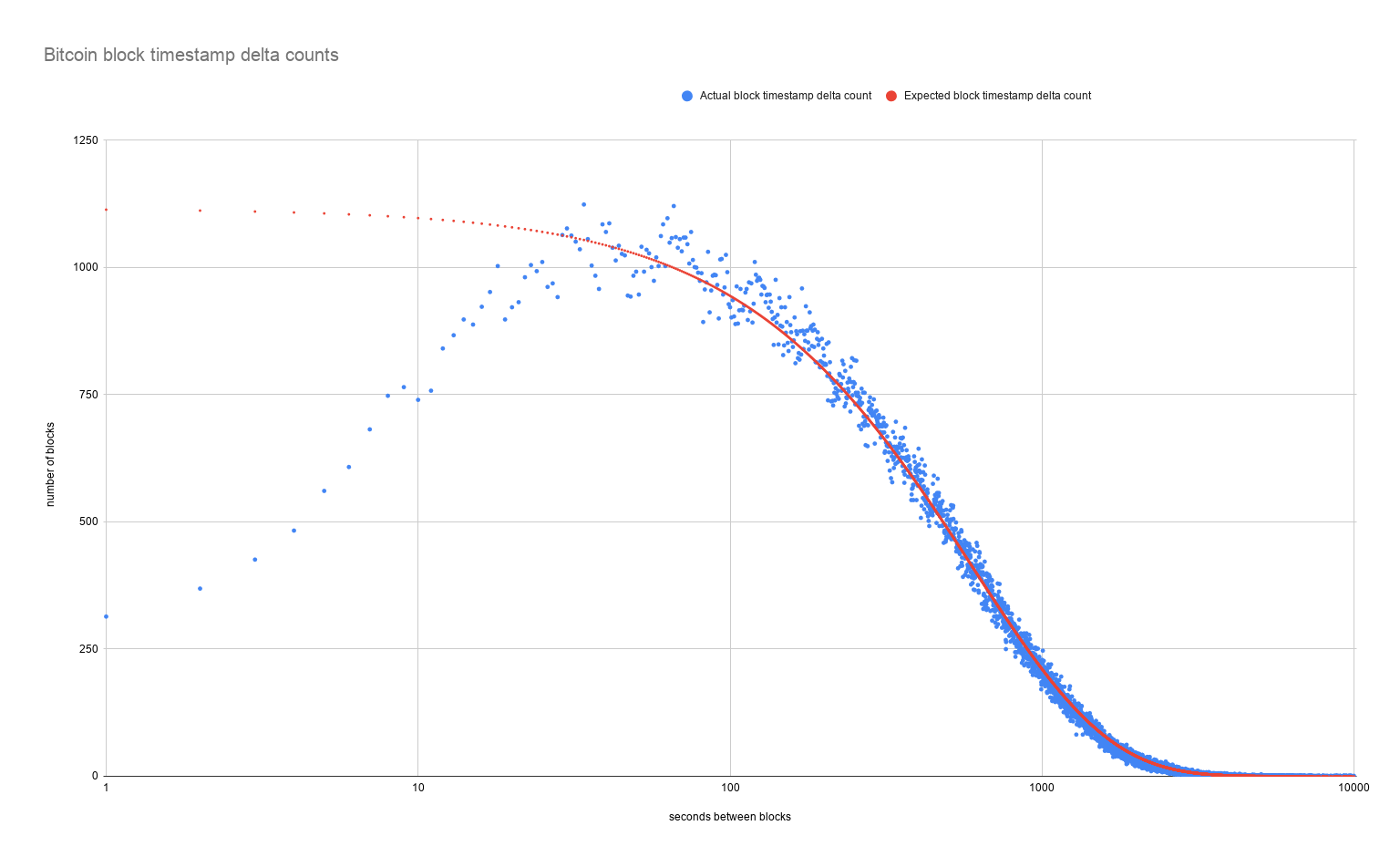
To discuss transaction inclusion times, we need to add another layer to the analysis. A naïve approximation would say that when a Bitcoin transaction is submitted, it should get included in the next block, which will on average arrive in 10 minutes; therefore, the inclusion time should be 10 minutes. In practice, the competitive nature of blockspace warps the dynamic and challenges the assumption of commutability.
The figure below shows the climb in pending transactions on September 2, 2022. Each cliff or drop-off in the chart indicates the discovery of a new block and the processing of a batch of the most valuable transactions. Conveniently, the vertical gridlines are at 10-minute increments—the average block time.
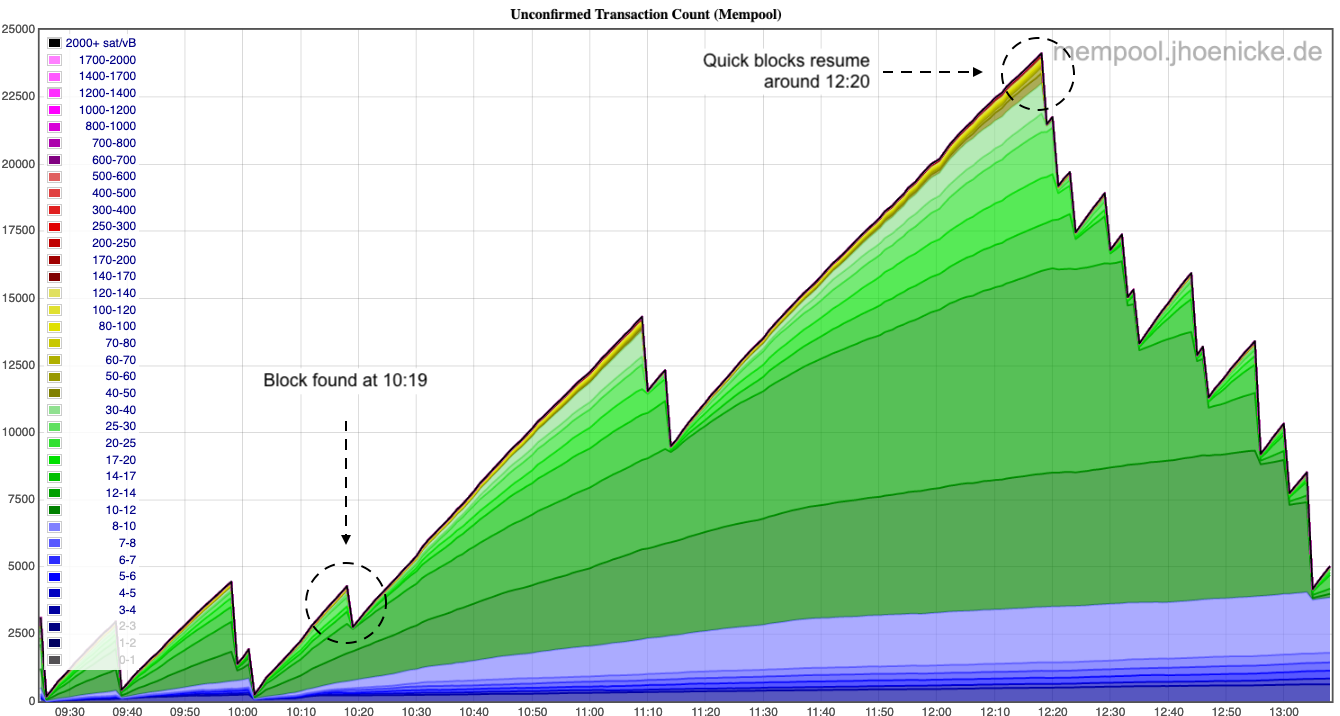
The figure demonstrates an atypical, but not rare, gap in block discoveries. From 10:20 to 12:18 there were only two blocks found, instead of the expected twelve.
Although it would have seemed safe to send a 12 sat/vB transaction at 10:20, it may not have been processed until 13:00, at least 8 and possibly as many as 11 blocks later. The two sources of delay are block time variance and asymmetric temporal information, i.e., transactions submitted later have the advantage of additional information and the ability to pay larger fees to jump the updated transaction queue.
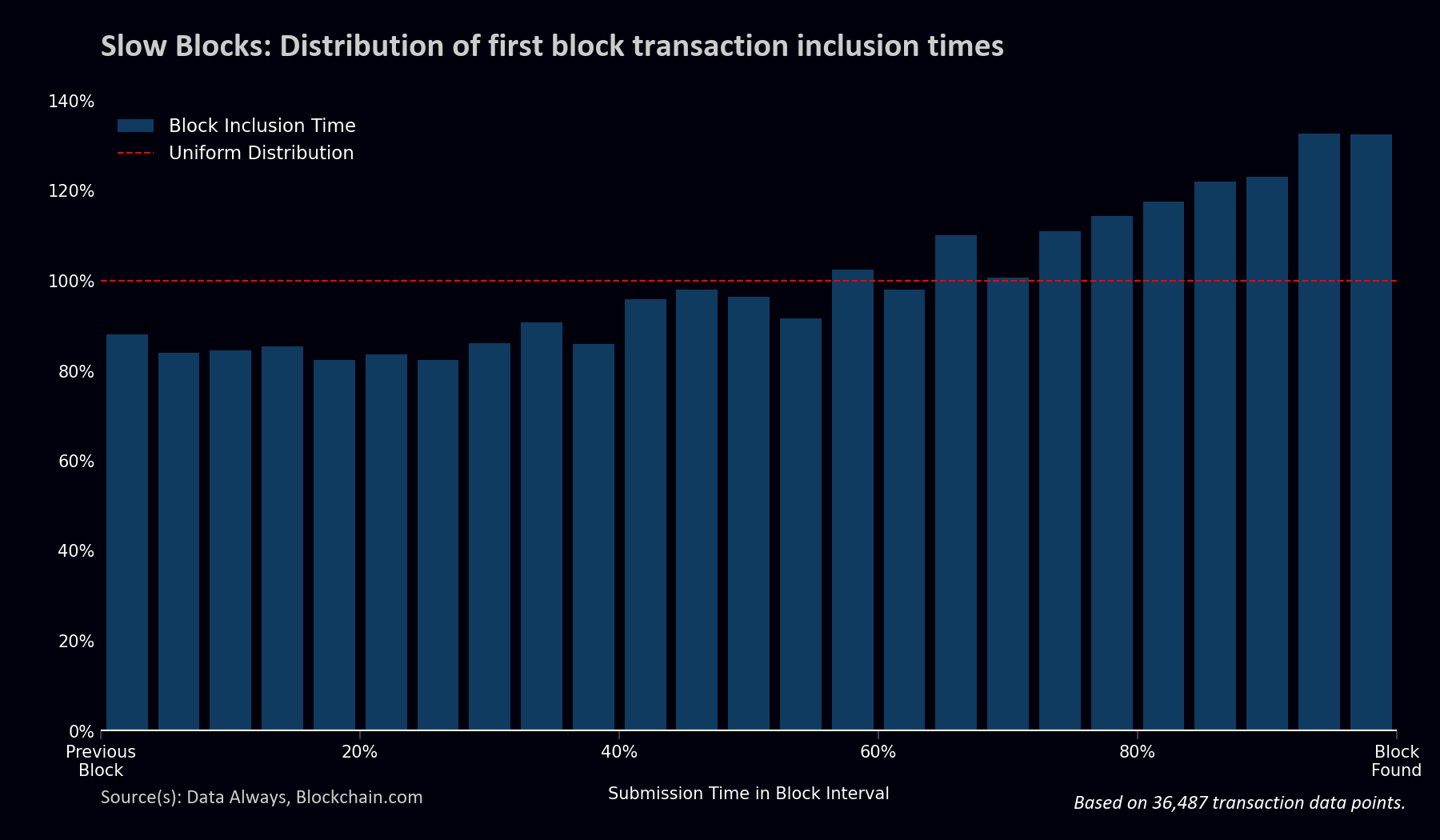
Taking a random sample of slowly discovered blocks and analyzing the transactions contained within, a clear pattern emerges between the submission time of transactions and the relative density of transactions that get included in the next block4. The slow blocks that were analyzed contained approximately 50% more transactions from time bins immediately preceding the discovery of the block than from bins immediately following the previous block.
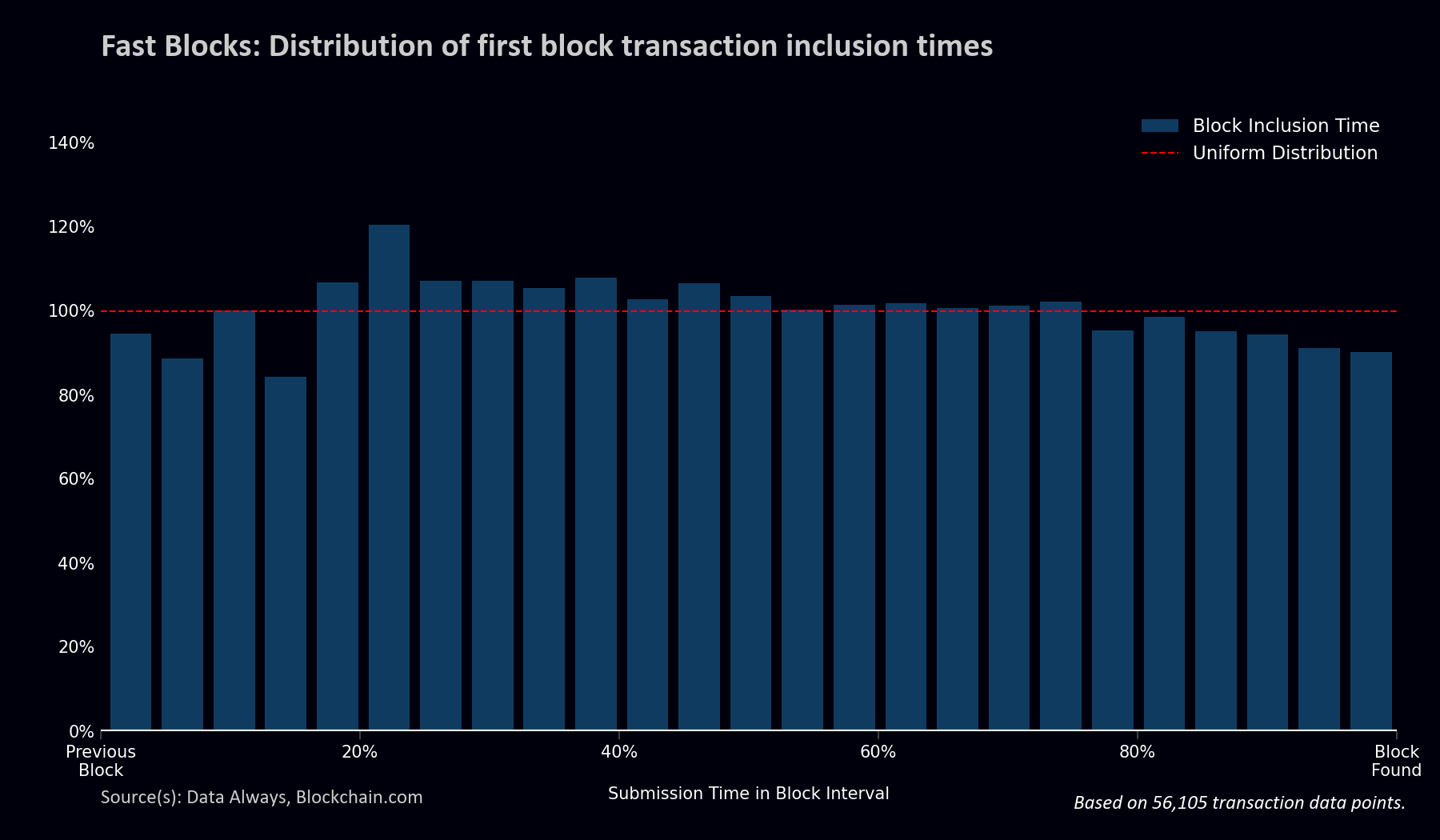
In heavy contrast, if we look at blocks that are discovered more quickly, the distribution of submission times is much more uniform5. The suggestion is that in fast blocks there is no meaningful temporal competition.
Most blocks are found quickly, so does any of this even matter?
If we calculate the expected block time, the contribution of long-tail blocks is actually surprisingly heavy. If one calculated the average block time but ignored 20+ or 30+ minute blocks as outliers, the expected block time would fall to only 6 or 8 minutes.
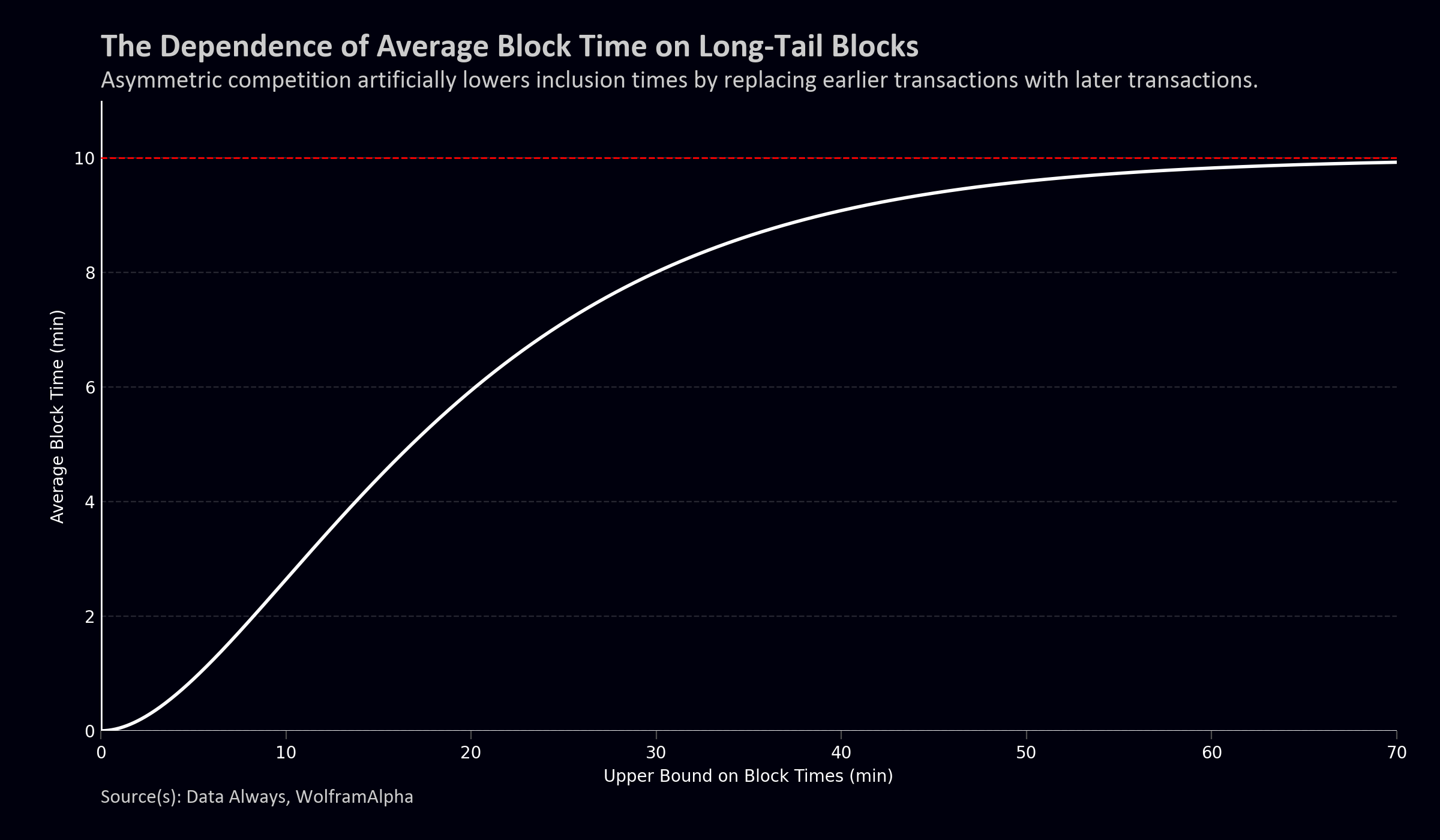
With respect to inclusion times, the temporal competition for blockspace essentially discards these long-tail blocks. For example, if we assume that transactions older than 20 minutes get replaced by fresh higher fee transactions, the average inclusion time for transactions making it into the first possible block should theoretically fall to only 6 minutes.
Realistically the fall isn’t all the way to 6 minutes. We saw in the slow blocks distribution that there wasn’t a full replacement, but I would expect the first block inclusion time to probably be in the 8-9 minute range, rather than the naïve 10-minute approximation.
Further accounting for the replaced transactions would require much more comprehensive data analysis than this writing will provide (heavily dependent on trends in blockspace demand, subsequent random rolls of block intervals, etc.). The result is likely a multimodal harmonic distribution.
Jumping back to proof-of-stake Ethereum, assuming non-competitive blockspace, the invariant 12-second block intervals would suggest an average inclusion time of 6 seconds6 (vs. 13 seconds in proof-of-work).
However, Ethereum blockspace is hyper competitive.
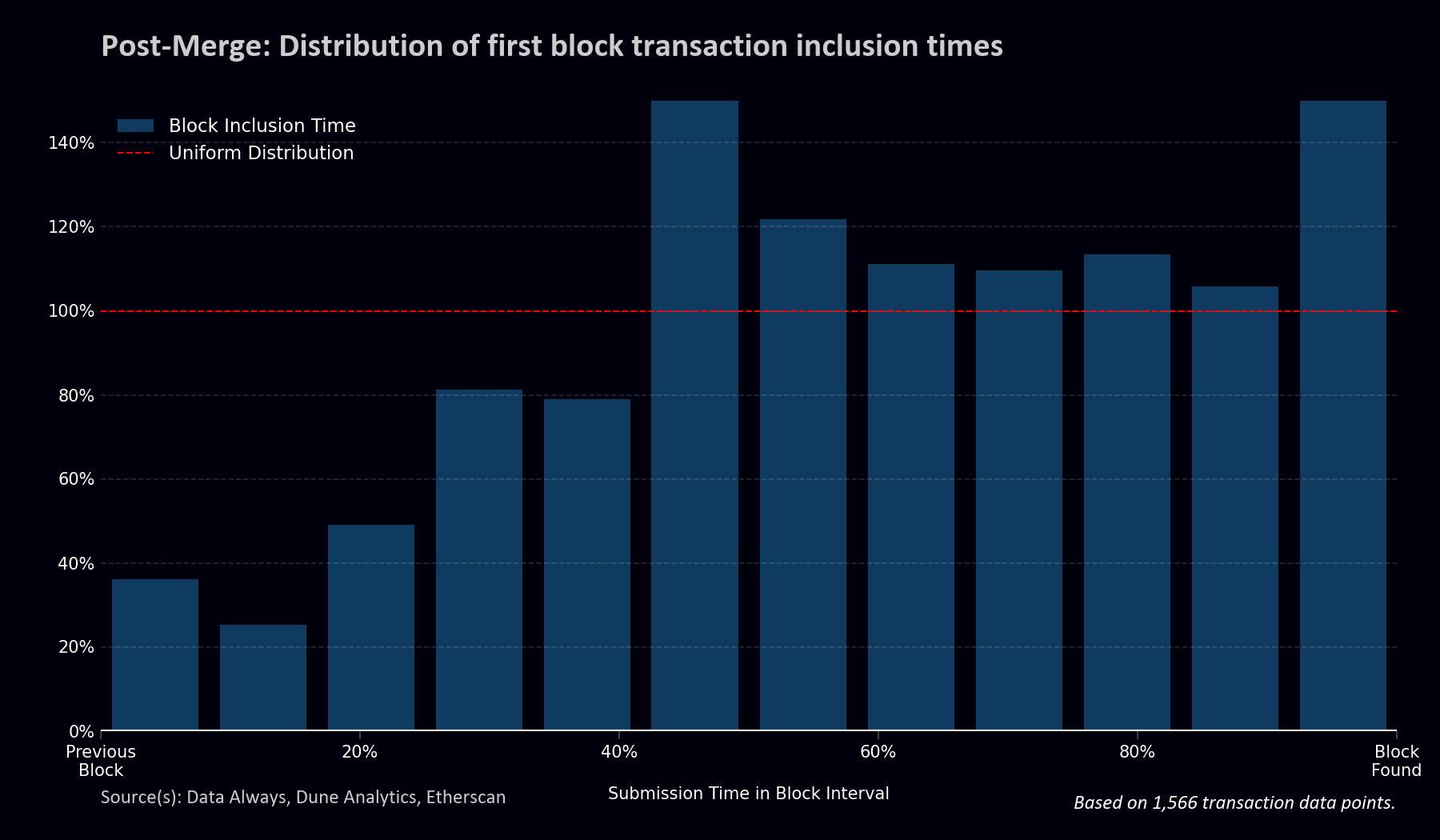
Even with constant block intervals, we appear to see strong temporal competition that even exceeds long-tail Bitcoin blockspace competition. All of this taking place within seconds, on repeat every 12 seconds.
So, are inclusion times lower? I guess it would depend on how any given person defines an inclusion time. If first-block inclusions on Ethereum are dominated by transactions submitted within the last few seconds of a block interval, then it isn’t clear to me that the drop in variance would make a meaningful difference. On the other hand, if we’re talking about a single transaction with a priority fee sufficiently overbid to ensure inclusion, then the expected inclusion time should have been reduced from 13 seconds to 6 seconds7.
- Variance in exponential probability distributions scales with the square of block time, so the variance of bitcoin block times is (600/13)^2 = 2130x greater than Ethereum PoW blocks. Perhaps this explains the relative lack of analysis of Ethereum block times.
- This metric assumes that Ethereum isn’t on the cusp of a hard fork where block times begin to increase exponentially to force miners to adopt the change.
- 30 day mean hash rate as of writing was 250.75 million TH/s, so in one 10 minute block there are 250.75×E6×E12×(60×10) = 1.5E23 hash attempts. To find a coin flip equivalent we take a base-2 log which comes out to 76.9 consecutive coin flips.
- Slow blocks in this sample were a pseudorandom series of 40 blocks with block intervals between 42 and 75 minutes discovered between December 22, 2022 and January 12, 2023.
- Fast blocks in this sample were a pseudorandom series of 86 blocks with block intervals between 2.5 minutes and 6 minutes discovered between December 22, 2022 and January 12, 2023.
- Invariant if we ignore empty blocks due to mistakes made by validators.
- Unfortunately, my pre-Merge data appears unreliable, although that could simply be artifacting from the hyper competitive nature of blockspace superimposed with block time variance. I’m not confident enough to post it.