



This article attempts to discuss the development and evolution of Rollup Layer2 from an evolutionary perspective, mainly addressing the following questions:
- How does Rollup work?
- Modular evolution of Rollup
- Possibilities brought by Modular
- Technological trends in modular application
- Conclusion
How does Rollup work?
The “trilemma” of blockchain has always been a difficult problem in the industry. If we consider that Layer1 blockchain should first ensure “decentralization” and “security,” migrating the “scalability” solution out of Layer1 is a natural choice, hence Layer2. The new problem is how to ensure the security of Layer2 through Layer1.
Initially, there was an idea to periodically write the state tree root of the Layer2 application to Layer1, which could verify the application state through state proof, similar to the reserve proof of CEX. However, third parties cannot verify that two state transitions are correct in a public manner using this approach.
To further explore this problem, let’s abstract it. The state of any program can be expressed through a state transition formula:
σt+1 ≡ Υ(σt, T)
This formula comes from the Ethereum Yellow Paper, but it can represent any program. Here, Υ represents the program, and σ represents the state. State σt+1 is calculated by program Y through state σt and transaction T. Transaction T represents the input to the program. At any time, if σt is deterministic, Y is deterministic, and T is deterministic, then σt+1 is deterministic.
So to provide public verifiability, the key is for Y to be publicly available, all historical T to be publicly available, and for their order to be determined. The intermediate states can be recalculated through Y and T. We can achieve the public availability of the program through open source, but how to ensure the public availability of T is another issue, which introduces the concept of data availability (DA).
Data availability requires a publicly available and immutable ledger to record the transactions of the application. The blockchain ledger is a system that naturally comes to mind. Therefore, writing Layer2 transactions back to Layer1 to ensure data availability is the origin of the name Rollup.
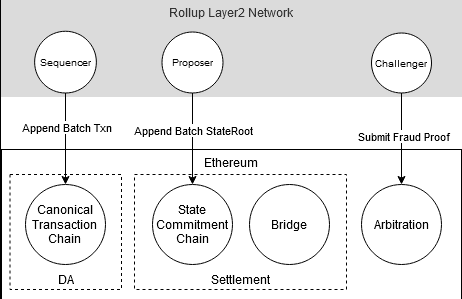
Therefore, a role is needed in the Layer2 system to collect users’ transactions, sort them, and write them to DA. This role is called the Sequencer. The transaction sequence here is called the Canonical Transaction Chain.
With data availability guaranteed, everyone can obtain the final state by running the program to execute transactions. However, consensus has not been reached yet, as everyone is uncertain whether the results obtained by them are consistent with those of others, as software or hardware failures can lead to data inconsistency. Therefore, another role is needed to periodically publish the state tree root after executing transactions, which can be used by everyone to verify their own state. This role is called the Proposer. The submitted state also forms a state sequence corresponding to the transaction sequence, called the State Commitment Chain.
At this point, we have achieved the verifiability of the application. But if someone’s result is inconsistent with the state submitted by the proposer, and it is determined that the problem is not with themselves, then it means the proposer cheated or made a mistake. How can others know about this? This requires the role of an Arbitrator. The arbitrator needs to be a trusted third party, which can be fulfilled by a contract on the chain.
There are two arbitration schemes for rollups:
- Each time the Proposer submits a state, they also provide the validity proof, which proves the validity of state transition between the current state and the previous one, and is verified by the arbitration contract on-chain. The validity proof is generated using zero-knowledge techniques, which is called ZK Rollup.
- Assuming the Proposer’s results are correct, but if inconsistencies are found, fraud proof is submitted, which is judged by the arbitration contract. If the arbitration contract determines that the Proposer has cheated, the Proposer will be penalized, and the State Commitment Chain will be rolled back to the state before the fraudulent transaction. Of course, to ensure safety, a relatively long challenge period is usually set to achieve the final settlement of on-chain transactions. This is called Optimistic Rollup.
We also need to achieve asset interoperability between Layer1 and Layer2. Therefore, we build a bridge between Layer1 and Layer2, and use state proofs for asset settlement between them. Layer2’s state root on Layer1 is guaranteed by Layer1’s arbitration contract, so the security of this bridge is also guaranteed by the arbitration contract.
At this point, we have obtained a Rollup Layer2 solution secured by Layer1 which allows for asset interoperability with Layer1.
Of course, the Rollup solution has made some compromises:
- Writing transactions to Layer1 means that the scalability of Layer2 is still limited by Layer1’s block size. For example, in Ethereum, if a Layer2 fully occupies all Ethereum blocks, the average TPS it can provide is only a few hundred, and its scalability is limited by DA.
- In order to save gas fees, the Sequencer will batch transactions into DA. Before writing to DA, the Sequencer may cheat by adjusting the order of transactions.
Here’s a summary of the security and finality of transactions in Layer2:
- If a user runs a Layer2 node and executes transactions in the order provided by the DA, the user can assume that the transactions are instantly confirmed and eventually settled because if the result of the user’s execution differs from that of the Proposer, it indicates that the Proposer cheated and the on-chain state needs to be rolled back, which will eventually match the result of the user’s own node. The main risk here is the risk mentioned earlier, which is the risk associated with the Sequencer adjusting the order of transactions that have not yet been written to the DA when syncing data in real-time.
- If a user cannot run a node themselves and relies on an RPC provider, the user needs to take on a certain level of trust risk. However, this risk is similar to the risk of trusting a Layer1 RPC node. The additional risk here is the risk of the Sequencer discarding or rearranging transactions.
- If the Proposer is wrong but no node initiates a challenge and the challenge period expires, the incorrect state cannot be rolled back, and the state can only be repaired through a hard fork by social consensus.
Modular evolution of Rollup
Based on the previous analysis, in the Rollup solution, multiple contracts on the chain play different roles and represent different modules. It is natural to think about whether modules can be split across multiple chains to achieve higher scalability. This is the idea of modular blockchain and modular Rollup.
Modular has two meanings here:
- Through modular design, the system becomes a plug-and-play system. Developers can meet different application scenario requirements through module assembly.
- Based on the ability provided by 1, the implementation of the modular layer is not bound to the same Layer1, thus obtaining better scalability.
There are three main modular layers that we can consider:
- Data Availability Layer: Ensures that the transaction data of the execution layer can be obtained in a public way, and ensures the transaction sequence.
- Settlement Layer: Implements asset and state settlement between Layer1 and Layer2. It includes the State Commitment Chain and the Bridge.
- Arbitration Layer: Verifies fraud proofs and makes judgments (optimistic) or verifies valid proofs (ZK). The arbitration layer must have the ability to manipulate the State Commitment Chain.
DA Modular
By migrating the DA function out and using an independent solution, the primary benefit is that the transaction gas fee of Layer2 is reduced by at least one order of magnitude.
From a security perspective, even if the decentralization of the DA chain is weaker than Ethereum, the main guarantee of the security of the DA layer is the transactions during the challenge period. After the challenge period, the DA is mainly used to facilitate other nodes to synchronize data, and it does not have a security guarantee. Therefore, the requirement for decentralization can be reduced by one level.
A DA dedicated chain can provide higher storage bandwidth and lower storage costs, and can be specifically designed for multiple applications to share the DA. This is also the foundation of current DA chains like Celestia and Polygon Avail.
After splitting the DA layer, we obtain the architecture shown in the figure below:

In the above figure, the DA is responsible for saving the Canonical Transaction Chain, and Layer1 is left with an L1ToL2 Transaction Queue to implement message communication between Layer1 and Layer2. Users can also write transactions directly to this queue to ensure the Layer2 is permissionless and that the Sequencer cannot audit users or transactions.
However, a new problem arises here. If the transaction sequence written by the Sequencer into the DA and the transaction sequence executed by the Proposer are inconsistent, how will the arbitration contract judge? One solution is to have a cross-chain bridge between the DA chain and the arbitration chain, which verifies the data proof provided by the DA chain in the arbitration contract. However, this solution depends on the implementation of cross-chain bridges between the DA and other chains, and the DA solution selection will be restricted. Another solution is to introduce Sequence proof.
Sequence Proof
We can think of Sequencer as part of the DA solution. It is equivalent to an app-specific DA and has the following responsibilities:
- Sequencer needs to provide DA guarantees for the time period before batch the transactions into the DA chain.
- Sequencer needs to verify, sort, and finally write transactions into the DA.
If Sequencer generates a Sequence Proof for each transaction, it can solve two problems:
- It provides a guarantee for transactions that have not been written into the DA chain, making it difficult for Sequencer to arbitrarily adjust the order or discard transactions.
- If there is no cross-chain bridge between the DA chain and the arbitration chain, the availability of data can be ensured through the challenge mechanism of Sequence Proof.
Sequence Proof has the following characteristics:
- It carries the signature of the Sequencer, proving that it was issued by a specific Sequencer.
- It can prove the position of a transaction in the entire transaction sequence.
- It is a type of accumulator proof. Each transaction generates a new accumulation result after being accumulated, which is related to all historical transactions before it. This makes it difficult to tamper with the results. One of the optional solutions for the accumulator is the Merkle Accumulator, and the accumulation result is represented by the root of the Merkle Tree.
How Sequence Proof works:

A user or an execution node submits a transaction to the Sequencer. The Sequencer returns the Sequence Proof to the user and synchronizes it with other nodes. If the Sequencer discards or changes the order of transactions before submitting them to the DA, the user or other nodes can submit the Sequence Proof to the arbitration contract to slash the Sequencer. The arbitration contract needs to read the root of the transaction accumulator from the State Commitment Chain contract to verify the Sequence Proof.
Let’s discuss the following scenarios:
- Sequencer discards or rearranges user transactions, which leads to the Sequencer generating two Sequence Proofs at the same position. The user submits the Sequence Proof to the arbitration contract, and the Sequencer needs to provide proof that the transaction is included in the root of the latest transaction accumulator. If it cannot provide the proof, it will be slashed.
- Sequencer fails to write transactions into the DA chain correctly and colludes with the Proposer to hide transactions. If there is a bridge between the DA chain and the arbitration chain, verification can be done through the bridge to slash the Sequencer. Otherwise, the user can initiate a challenge to require the Sequencer to provide proof of a transaction’s position and original information. In this case, the arbitration contract cannot judge whether the user is making a malicious challenge, so the Sequencer will not be slashed if it provides the data. For users, making a malicious challenge is not beneficial and lacks economic incentives.
By introducing Sequence Proof, Layer2 protocols become more secure.
Transaction Pipeline and Parallel Execution
By assigning the Sequencer to the DA to solely handle transaction validation and sorting, another benefit is that it is easy to implement a transaction pipeline and parallel execution.

When validating a transaction, it is necessary to verify the signature and whether there is sufficient gas fee, and gas fee verification relies on the state. If we allow the Sequencer to verify transactions with a certain delay (in seconds) between the dependent state and the latest state to ensure that validation transactions are not blocked by executing transactions, then gas verification may be inaccurate and at risk of DDoS attacks.
However, we believe that assigning the Sequencer to the DA is a correct direction, so it is worth further research. For example, the DA part of the transaction fee can be split out and expressed through the UTXO (Sui Move Object) to reduce the cost of gas fee checking.
The Sequencer sorts the transactions and outputs them into a transaction pipeline, which is then synchronized to the Proposer and other nodes. Each node can choose a parallel execution scheme based on its own server situation. Each node needs to ensure that only transactions without causal relationships are executed in parallel, and transactions with causal relationships must be executed in the order of the Sequencer, so that the final result is consistent.
The Proposer needs to periodically submit the root of the state tree and the root of the accumulator to the State Commitment Chain contract on the chain.
So we have a modular Layer2 with low gas fees, high TPS, and greater security, this is Rooch.

- MoveOS: It includes MoveVM and StateDB, which are the system’s execution and state storage engines. StateDB is built with two layers of Sparse Merkle trees and can provide state proofs. As mentioned earlier, the state tree and state proof are indispensable components of Rollup applications.
- RPC: Provides query, transaction submission, and subscription services to the outside world. Can be compatible with other chain’s RPC API through proxying.
- Sequencer: Verifies transactions, sorts transactions, provides sequence proof, and streams transactions into the transaction pipeline.
- Proposer: Retrieves transactions from the transaction pipeline, batch executes them, and periodically submits them to the State Commitment Chain on the chain.
- Challenger: Retrieves transactions from the transaction pipeline, batch executes them, compares them with the State Commitment Chain, and decides whether to initiate a challenge.
- DA & Settlement & Arbitration Interface: Abstracts and encapsulates different modular layers to ensure that switching between different implementations does not affect the upper-level business logic.
Interactive Fraud Proofs with Multi-Chain Support
In the Optimistic Rollup solution, it has always been a challenge for on-chain arbitration contracts to determine when off-chain transactions have been executed incorrectly. The initial idea was to re-execute Layer2 transactions on Layer1, but the difficulty with this approach is that Layer1 contracts would have to simulate Layer2 transaction execution, which would be costly and limit the complexity of Layer2 transactions.
The industry eventually came up with an interactive proof scheme. Since any complex transaction ultimately boils down to machine instructions, if we can identify the diverging instructions, we can simply simulate the execution of instructions on the chain.
Using the same state transition formula as before:
σt+1 ≡ Υ(σt, T)
where Υ represents an instruction, T represents instruction input, and σ represents the memory state that the instruction depends on. If a state proof is generated for each σ during execution, the two parties in a dispute can interactively identify the divergence point m, and submit state σ m-1 and instruction m to the on-chain arbitration contract for simulation. The arbitration contract can then provide a judgement after execution.
The remaining question is how to generate the proof, and there are mainly two approaches:
- Implement it directly in the contract language virtual machine, such as Arbitrum’s AVM and Fuel’s FuelVM.
- Implement a simulator based on an existing instruction set, which can provide proof capabilities within the simulator. For example, Optimism’s MIPS-based cannon, Arbitrum’s new WASM-based Nitro, and Rooch’s MIPS-based OMO.
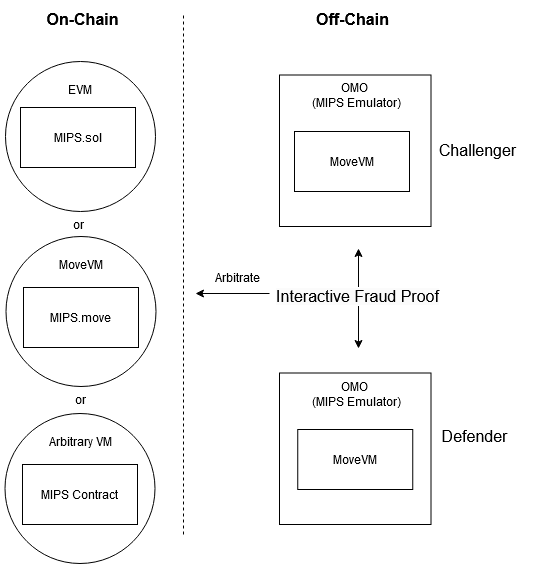
OMO is a general bytecode simulator with single-step state proof capabilities, designed for multi-chain execution environments. With support from OMO, the arbitration layer can be modular. Any chain that supports Turing-complete contracts can simulate OMO’s instructions in its contracts and act as an arbitration layer.
ZK + Optimistic Combination Solution
The industry has been debating the pros and cons of Optimistic Rollup and ZK Rollup, but we believe that combining the two can achieve the benefits of both solutions.
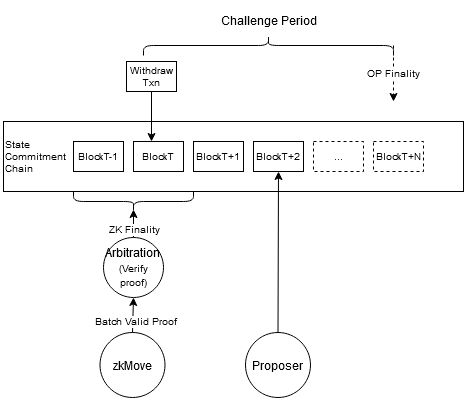
Based on the previous Optimistic solution, we introduce a new role, the ZK Prover. It generates valid proofs in bulk for the transaction states submitted by the Proposer, and submits them to the arbitration contract. After verification by the arbitration contract, the transaction can be settled from Layer2 to Layer1 for finality.
The advantages of this solution are:
- The overall throughput of Layer2 will not be limited due to the performance issues of ZK.
- ZK can shorten the challenge period of Optimistic and improve user experience.
Before the maturity of ZK solutions and hardware acceleration, we can build the ecosystem through Optimistic, and the modular solution can seamlessly integrate ZK in the future.
Multi-Chain Settlement
If we further consider the trend of modular, it naturally leads to the question of whether the settlement layer can be deployed on another chain, since the DA can be migrated to another chain.
The asset settlement between Layer1 and Layer2 mainly relies on two components, one is the Bridge, and the other is the State Commitment Chain. When settling through the Bridge, it is necessary to rely on the State Commitment Chain to verify the Layer2’s state proof. The Bridge can certainly be deployed on multiple chains, but there can only be one authoritative version of the State Commitment Chain, which is ensured by the arbitration contract.
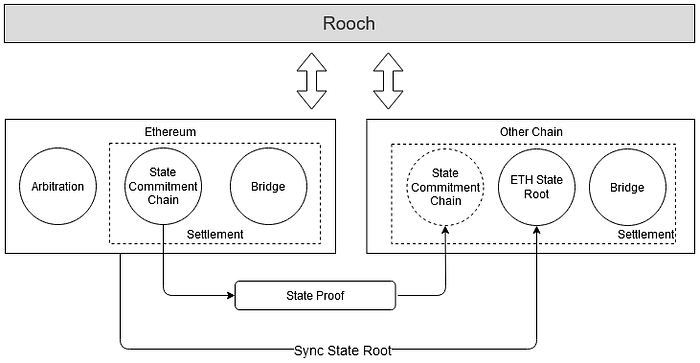
This direction requires further research, but there is a preliminary solution. The State Commitment Chain on other chains is a mirror of the arbitration chain (Ethereum). This mirror does not need to synchronize all Layer2 State Roots to other chains, but users can map them as needed through Ethereum’s state proof.
Of course, other chains also need to be able to verify the state proof on Ethereum, so they need to know the state root on Ethereum. Currently, there are two solutions for synchronizing Ethereum’s state root to other nodes: 1. relying on an Oracle. 2. embedding an Ethereum light node to verify Ethereum’s block header.

In this way, we can get a Layer2 solution that supports multi-chain settlement, but whose security is guaranteed by Ethereum.
The difference between this solution and cross-chain is:
- If it is a cross-chain solution that relies on a relay chain, Layer2 can be regarded as replacing the relay chain and is a relay layer with security guaranteed by the arbitration contract.
- If it is a cross-chain solution that verifies the state proof between chains, the multi-chain settlement solution shares the same technical solution for state root synchronization, but it is much simpler. Th synchronization requirement for state proofs is one-way in the multi-chain settlement solution, we only need to synchronize from the arbitration chain to other chains, rather than provide for two-way synchronization between each pair of chains.
Possibilities brought by Modular
Through modular, developers can combine Rooch with other components to create different applications.
- Rooch Ethereum Layer2 = Rooch + Ethereum (Settlement+Arbitration) + DA This is the network that Rooch will initially run on. It provides a Move execution platform that is secured by Ethereum and can interoperate with assets on the Ethereum network. It can be expanded in the future to support settlement on multiple chains.
- Rooch Layer3 Rollup DApp = Rooch + DApp Move Contract + Rooch Ethereum Layer2 (Settlement+Arbitration) + DA If an application deploys its settlement and arbitration to Rooch Layer2, it becomes a Rooch Layer3 application.
- XChain Rollup DApp = Rooch + DApp Move Contract + XChain (Settlement+Arbitration) + DA Any chain can provide developers with a Move-based Rollup DApp toolkit through Rooch. Developers can write their own application logic in Move language, and run a Rollup application with security guaranteed by XChain, and can interoperate with assets on XChain. Of course, this requires collaboration with developers from each public chain.
- Sovereign Rollup DApp = Rooch + DApp Move Contract + DA Applications can also use Rooch as a Sovereign Rollup SDK, without deploying the Bridge and Arbitration contracts. The State Commitment Chain is also saved on DA to ensure verifiability, with security ensured by social consensus.
- Arweave SCP DApp = Rooch + DApp Move Contract + DA (Arweave) The SCP and Sovereign Rollup have similar ideas, where SCP requires the application code to be saved in the DA layer. In Rooch, contract deployment and upgrade are both transactions, and the contract code is in transaction, is written to the DA layer, so we believe it meets the SCP standard.
- Move DApp Chain = Cosmos SDK + MoveOS + DApp Move Contract MoveOS can be embedded as an independent Move execution environment in the runtime environment of any chain to build application chains or new public chains.
- Non-Blockchain Projects Non-blockchain projects can use MoveOS as a database with data verification and storage proof capabilities. For example, it can be used to build a local blog system, where data structure and business logic are expressed through Move. As the infrastructure matures, it can be directly integrated into the blockchain ecosystem. Another example is using it for FaaS services in cloud computing, where developers write functions in Move, and the platform manages the state. Functions can be combined and called. There are more possibilities to be explored.
Rooch’s modular design can adapt to applications of different types and stages. For example, developers can first validate their ideas by deploying contracts on the Rooch Ethereum Layer2, and then migrate the application to an independent App-Specific Rollup when it grows up.
Alternatively, developers can start the application directly through the Sovereign Rollup method, because in the early stages of the application, there is no high requirement for security, and there is no need to interoperate with assets on other chains. Later, as the application grows, and the need to interoperate with assets arises, and the security requirement increases, Settlement and Arbitration modularity can be enabled to ensure the security of the assets.
Technical Trends of Modular Applications
Potential of DA has yet to be tapped
From the previous analysis, it can be seen that regardless of the combination method, it depends on the DA layer. The role of the DA layer in decentralized applications is similar to the log platform in Web2 systems. It can be used for auditing, supporting big data analysis, and conducting AI training. Many applications and services will be built around the DA layer in the future. Currently, there are already DA chains such as Celestia, Polygoin avail, and there will be more in the future, such as EigenLayer, Ethereum danksharding, and so on.
According to the previous analysis, we conclude that the role of the Sequencer should belong to a part of the DA layer. If the DA layer can provide transaction verification capabilities for applications and has sufficient performance, the Sequencer’s responsibilities can actually be fully borne by the DA layer, and users can directly write transactions to the DA layer. Of course, whether users can pay the Gas fee for DA with the application’s token is another problem that needs to be solved.
DApp programming languages will explode
New application forms will promote the explosion of new programming languages, as already seen in the Web2 era. Move will become the best language for building Web3 DApps. In addition to Move’s language features, the following reasons are based on:
- Using the same language for DApps can quickly accumulate the basic libraries needed for the application and form an ecosystem effect. Therefore, supporting multiple languages at the beginning is not a good strategy.
- Decentralized applications must ensure verifiability at least, and smart contract languages can reduce many mental burdens for developers in ensuring verifiability.
- Move’s platform-agnostic nature makes it easy to adapt to different platforms and applications.
- Move’s state is structured, which is beneficial for DApp’s data structure expression and storage retrieval.
Conclusion
I entered the blockchain industry at the end of 2017. at the time, many teams were trying to build applications on the blockchain. Unfortunately, the infrastructure was not yet complete and the industry had not yet figured out a replicable pattern for building applications. Most application-based projects failed, which was a blow to developers and investors. How should applications be built on the blockchain? This question has been on my mind for five years.
Now, with the maturity of Layer1, Layer2, and smart contracts, as well as modular infrastructure, the answer to this question has become gradually clearer.
I hope that in the upcoming wave of Web3 DApp explosion, Rooch can help developers build applications faster and truly land them.