

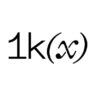

This article covers core concepts in decentralized identity, the evolution of identity on the internet, a layer-by-layer overview of the web3 identity infrastructure stack, and related developments in privacy primitives. Proof-of-Personhood, compliance, and the application layer will be covered in a future article.

Identity is an emergent property consisting of data associated with a person, entity, or an object. In the physical world, we hold this data in our brains in the form of abstract reputation and mental associations. In the digital world, identity is formalized into 2 components:
- The identifier: a unique set of characters or numbers that identifies a subject (e.g. passport number, Twitter id, student id)
- The data associated with that subject (e.g. travel history, tweets and follows, academic achievements)
Creating an identity layer for the internet is a hard problem because there is a lack of agreement on what it should be and how it should be run. Digital identity is related to context, and we experience the internet through many kinds of content which exists in at least as many different contexts. Today, much of our digital identity is fractured and under the control of a few parties whose interests are to prevent spillover from their context to any other.
- Corporations see customer relationships as key assets and are reluctant to give up control over these relationships. So far, no single approach has served as motivation to do so. Even ad hoc identity one-offs are better than a framework that is out of their control.
- Specific industries like finance have unique needs (e.g. compliance) when it comes to maintaining digital relationships with customers and vendors.
- Governments have needs that distinguish them from other kinds of organizations. For example, jurisdiction over drivers’ licenses and passports.
This paradigm has created a power asymmetry between individuals and the parties that manage our identities and data. It restricts our autonomy to consent, selectively disclose information about ourselves, and port our identities across contexts for a consistent experience both online and offline.
Decentralized identity has been a collective effort long before the rise of crypto and web3. The overarching goal is to give individuals back autonomy over their identity without relying on centralized, monolithic gatekeepers. Misuse of customer data and erosion of trust in large corporations has put decentralization at heart of the next era of internet identity.
Core Concepts in Decentralized Identity
Decentralized identifiers (DIDs) and attestations are primary building blocks of decentralized identity. DIDs are issued and stored on verifiable data registries (VDRs) which act as autonomous “namespaces” that are not centrally administered. In addition to blockchains, decentralized storage infrastructure and P2P networks can serve as VDRs.
Here, entities (individuals, communities, organizations) can authenticate, prove ownership of, and manage their DIDs using decentralized public key infrastructure (PKI), which unlike traditional Web PKI, do not rely on centralized certificate authorities (CAs) as the root of trust.
Data is written about identities as attestations — “claims” one identity makes about another (or themselves). Claim verifications are done using cryptographic signatures made possible by PKI.
Decentralized Identifiers have 4 main properties:
- Decentralized: No reliance on central authorities to create. Entities can create as many as they want, scoped to different contexts to maintain their desired separation of identities, personas, and interactions.
- Persistent: Permanently assigned to the entity once created. (Though some DIDs are designed for ephemeral identities)
- Resolvable: Can be used to reveal additional information about the entity in question.
- Verifiable. Entities can prove ownership of a DID or claims made about it (Verifiable Credentials) without reliance on third parties, thanks to cryptographic signatures and proofs.
These properties distinguish DIDs from other identifiers such as usernames (not verifiable), passports (not decentralized), and blockchain addresses (not persistent, limited resolvability).
The World Wide Web Consortium (W3C) is an international community of organizations, staff, and the public working together to develop Web standards. W3C’s DID Spec defines 4 main components:
- Scheme. The prefix “did” tells other systems that it is interacting with a DID and not other types of identifiers like a URL, email address, or product barcode.
- DID Method: specifies to other systems how to interpret the identifier. There are over 100 DID Methods listed on the W3C website, often associated with its own VDR and with differing mechanisms for creating, resolving, updating, and deactivating identifiers.
- Unique Identifier: a unique ID specific to a DID method. For example an address on a specific blockchain.
- DID Document: The 3 above pieces resolve to a DID Document, which contains the ways in which the entity can authenticate itself, any attributes/claims made about the entity, and pointers (“service endpoints”) to where additional data about the entity is locoated.
The Impact of Crypto
Although public key infrastructure (PKI) has been around for a long time, crypto has accelerated its adoption through incentive mechanisms in token networks. What was once predominantly used by privacy-conscious technologists is now a prerequisite to participate in a new economy. Users needed to create wallets to self-custody their assets and interact with web3 applications. With the carrots of the ICO boom, DeFi summer, NFT mania, and tokenized communities, more keys are in users’ hands than ever before. Along with this came a vibrant ecosystem of products and services that makes key management easier and more secure. Crypto has been the perfect trojan horse for decentralized identity infrastructure and adoption.
Let’s take wallets as a starting point. While wallets are still primarily thought about in the context of asset management in the financial sense, tokenization and on-chain histories have enabled us to represent our interests (NFT collection), work (Kudos, 101), and opinions (governance votes). Losing private keys is becoming less like losing money and more like losing a passport or social media account. Crypto has blurred the line between what we own and who we are.
However, our on-chain activity and holdings give a limited (and not privacy-preserving) view of who we are. Blockchains are just one layer of the decentralized identity stack. Others help tackle important questions like:
- How do we identify and authenticate ourselves across networks and ecosystems?
- How can we prove things about ourselves (reputation, uniqueness, compliance) while maintaining privacy?
- How do we grant, manage, and revoke access to our data?
- How do we interact with apps in a world where we control our own identities and data?
Solutions to these questions have profound implications on what the internet will look like for generations to come.
The following sections give a layer-by-layer overview of the web3 identity stack. Namely verifiable data registries, decentralized storage, data mutability & composability, wallets, authentication, authorization, and attestations.
The Web3 Identity Stack
Blockchains as Verifiable Data Registries
The distributed and immutable nature of blockchains render them suitable as verifiable data registries on which to issue DIDs. And indeed there exists W3C DID methods for various public blockchains such as:
- Ethereum, where did:ethr:<public key> represents Ethereum accounts as an identity
- Cosmos, where did:cosmos:<chainspace>:<namespace>:<unique-id> represents a Cosmos interchain-compatible asset
- Bitcoin, where did:btcr:<btcr-identifier> represents a TxRef encoded transaction id, in reference to a transaction position within the UTXO-based Bitcoin blockchain
Notable is did:pkh:<address> — a ledger-agnostic, generative DID method designed for interoperability across blockchain networks. <address> is the account id according to the CAIP-10 standard for keypair expression across chains.
Fractal is an identity provisioning and verification protocol designed for applications requiring unique and varying levels of KYC’d users. After completing liveness and/or KYC checks, a Fractal DID is issued to the corresponding Ethereum address and added to the appropriate list. Fractal’s DID registry is a smart contract on Ethereum, against which counterparties can lookup Fractal DIDs and their verification level.
Kilt, Dock, and Sovrin are application-specific blockchains for self-sovereign identity. At the time of writing, they are primarily being used by enterprises to issue identities and credentials to end users. To participate in the network, nodes are required to stake native tokens in order to process transactions such as DID/credential issuance, define credential schemas, and perform revocation updates.
Decentralized Data Storage
While general-purpose blockchains can also serve as a data source for immutable user data such as asset ownership and transaction history (e.g. for portfolio trackers and “DeFi score” apps), they are likely unsuitable for storing most data about users as writing and regularly updating large amounts of information is a costly operation, and compromises on privacy as the data is visible by default.
That being said, there are application-specific blockchains like Arweave* which are designed for permanent storage. Arweave pays block rewards and transaction fees to miners in exchange for replicating information stored on the network. Miners are required to provide “Proof-of-Access” in order to add new blocks. A portion of fees are also paid to a perpetual endowment, which will be paid out to miners in the future when storage costs are not covered by the inflation and fees.
Ethereum and Arweave are examples of blockchain-based approaches to data persistence. On Ethereum, each full node must store the entire chain. On Arweave, all data required to process new blocks and new transactions is memoised into the state of each individual block, allowing new participants to join the network by downloading only the current block from its trusted peers.
Contract-based persistence intuits that data cannot be replicated and stored perpetually by every node. Instead, data persists through contracts with multiple nodes who agree to hold a piece of data for a period of time and must be renewed whenever they run out to keep the data persisted.
IPFS allows users to store and transfer verifiable, content-addressed data in a peer-to-peer network. Users can persist the data they want on their own IPFS nodes, leverage dedicated groups of nodes, or use third party “pinning” services like Pinata, Infura, or web3.storage. Data exists in the network as long as one node is storing it and can provide it to others when they request it. Atop IPFS sits cryptoeconomic layers like Filecoin and Crust Network, designed to incentivize storing data for the network by creating a distributed marketplace for longer-term data persistence.
For Personally Identifiable Information (PII), permissioned IPFS could be used to comply with GDPR/CCPA right to be forgotten, as it allows users to delete their data stored in the network. Identity wallet Nuggets has adopted this approach, further decentralizing it by having merchants and partners run dedicated nodes.
Other contract-based decentralized storage solutions include Sia and Storj, which encrypts and splits individual files among multiple nodes across the network. Both use erasure coding (only requiring a subset of storage nodes to serve files) to ensure data availability even if some nodes go offline, and have built-in incentive structures for storage using a native token.
Data Mutation & Composability
General purpose blockchains, Arweave, and IPFS all guarantee immutability, a useful property for data like static NFT art and permanent records. However, our interactions with most applications today update our data on an ongoing basis. Web3 protocols designed for mutable data were created to enable just that, leveraging the decentralized storage layer underneath.
Ceramic is a protocol for decentralized data mutation and composability which works by taking immutable files from IPFS or persistent data storage networks like Arweave and turning them into dynamic data structures. On Ceramic, these “data streams” are akin to its own mutable ledger. Private data can be stored off-chain with its schema indexed on Ceramic, attached to the DID data store that routes to the external private storage.
When a user updates their profile in a Ceramic-powered application, the protocol validates those updates into a stream to transform that into a new state while keeping track of previous state changes. Every update on Ceramic is verified by a DID that can map to multiple addresses, paving a way for users to update their data without servers.
Today, web2 monoliths own the UI and backend where they store and control user data. Google and Facebook use this data to algorithmically personalize our experience on their platforms, further productising data they have collected. New applications have to start the onboarding process from scratch and cannot deliver personalized experience from the get go, making the market less competitive.
Web3 democratizes data and levels the playing field for new products and services, creating an open environment for experimentation and competitive markets for apps. In a world where users can bring data with them from platform to platform, app developers don’t need to start from a blank state to give users a personalized experience. Users can log in with their wallets, and authorize apps to read/write to their “data vaults” that they have full control over.
ComposeDB on Ceramic is a decentralized graph database that enables application developers to discover, create, and reuse composable data models using GraphQL. The nodes in the graph are either accounts (DIDs) or documents (data streams). The edges in the graph represent relations between nodes.
DIDs represent any entity that can write data to the graph e.g. end-users, groups, applications or any kind of authenticated service.
Models are Ceramic streams that store metadata about a document’s data structure, validation rules, relations, and discovery information. Developers can create, compose, and remix models to form data Composites that act as a database for their application. This replaces the traditional user table where you have centralized UIDs and (siloed) associated data. Apps can build on top of public datasets controlled by the user instead of managing their own siloed tables.
As applications can permissionlessly define schemas they will use for a given context, curation markets become important as it provides a signal for the most useful data models (defined schemas for a social graph, blog posts etc.). With a marketplace on these data models, apps can signal the models which makes it more consumable. This incentivizes public data sets that will produce better analytics and information graphs for products to further innovate on top of.
Tableland is infrastructure for mutable, structured relational data where each table is minted as an NFT on an EVM-compatible chain. The owner of the NFT can set Access Control Logic for the table, allowing third parties to perform the updates on the database if that party has the appropriate write permissions. Tableland runs an off-chain validator network that manages the creation and subsequent mutations to the table.
On-chain and off-chain updates are handled by a smart contract that points to the Tableland network using the baseURI and tokenURI. With Tableland, NFT metadata can be mutated (using access controls), queried (using SQL), and is composable (with other tables on Tableland).
Similar to how smart contract standards like ERC-20 and ERC-721 have given dapps a shared language for how we create and transfer tokens, data model standards give a shared understanding between apps about data such as profiles, reputation, DAO proposals, and social graphs. With open registries that anyone can submit to, this data can be reused by multiple applications.
Decoupling applications from the data layer allows users to port their own content, social graph, and reputation between platforms. Applications can tap into the same databases and use it within their context, enabling users to get a composable reputation across contexts.
Wallets
Broadly speaking, wallets consist of the interface and underlying infrastructure for key management, communication (data exchange between the holder, issuer, and verifier), and claims presentation and verification.
It’s worth making a distinction between crypto wallets (MetaMask, Ledger, Coinbase Wallet etc.) and identity wallets. Crypto wallets store cryptographic keys specific to a blockchain network and are designed for sending/receiving tokens and sign transactions. Identity wallets store identities and allow users to create and present claims such that they can present identity data across applications and services.
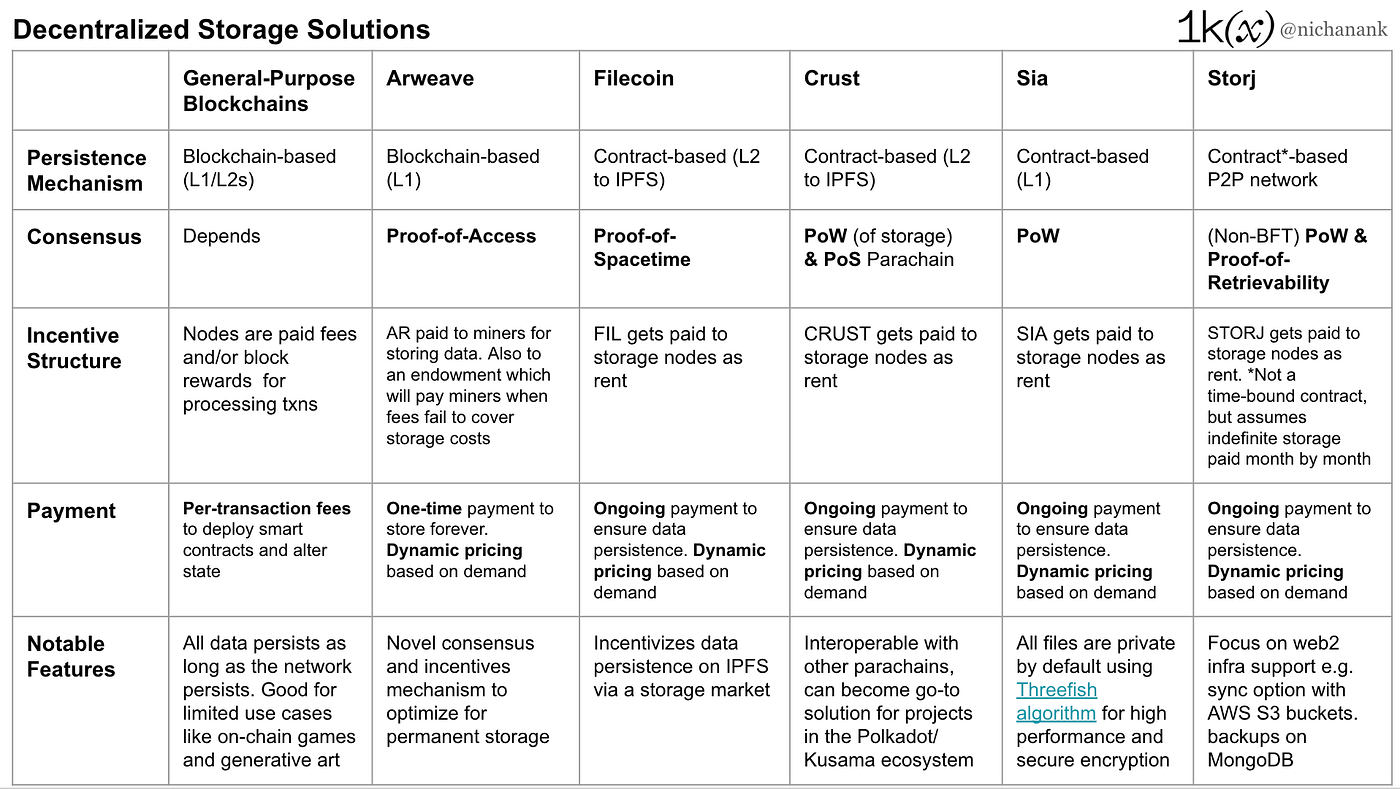
Examples of identity wallets include ONTO, Nuggets, and Polygon ID Wallet. Some identity wallets like Fractal have liveness checks and KYC as part of their onboarding flow, so users can have a claim to present to applications that have such requirements. This is much less common for crypto wallets. Identity wallets are also more likely to support W3C-recognized implementations of DIDs, Verifiable Credentials, and DIDComm and use cases outside of web3.
WalletConnect* is a communications protocol connecting wallets one another wallets and to dapps. As a minimalistic, unopinionated protocol already serving millions of cryptonative users, WalletConnect may prove a powerful alternative to DIDComm in accelerating the adoption of self-sovereign identity infrastructure. Unlike DIDComm which requires hosting mediator infrastructure from service providers, WalletConnect stores messages in a “cloud mailbox” in a relay network which pushes these messages to wallets when they come back online.
Authentication
Authentication confirms a user’s identity based on one or more authentication factors. A factor can be something that the user owns (digital signature, ID card, security token), something that they know (password, PIN, secret answer) or biometrics (fingerprint, voice, retina scan).
In the decentralized identity paradigm, the user can authenticate themselves using their wallet. In the background, the wallet uses the key it stores to produce a digital signature that serves as “proof” that the holder owns the private key associated with that account. Because crypto wallets can produce signatures, applications that offer web3 login are able to let users authenticate with their Metamask or WalletConnect.
For years, cryptonatives interacted with dapps through “Connect Wallet”, a basic operation to specify which account they want to use it with. The dapp remembers nothing about the connected user and treats them as a blank slate each time they visited the site.
Today, users have deeper modes of interaction with dapps. Decentralized identity infra becomes useful here because it allows applications to gain access to more context around the user, and thus offer personalized experiences while letting individuals retain control of their own data.
For richer contextual interactions such as loading user preferences, profiles, or private chat messages, applications need to first ensure it’s talking to the actual keyholder behind the account. While “Connect Wallet” does not provide this guarantee, authentication standards do. Authentication establishes a session with the user and allows apps to securely read and write their data.
Sign-In with Ethereum (SIWE) is an authentication standard spearheaded by Spruce, ENS, and the Ethereum Foundation. SIWE standardizes a message format (similar to jwt) for users to log in to services using a blockchain-based account. Sign-In with X (CAIP-122) builds on this to make SIWE an Ethereum-focused implementation of SIWx, generalizing the standard to work across blockchains.
For individuals, this means the ability to sign up or login with their web3 wallets without creating a username and password with “few clicks” UX mimicking that of social logins while maintaining sovereignty over their online identity. Applications can incorporate this as a go-to-market strategy for a web3-native audience, meeting users where they are.
In the medium term, the ability to use crypto wallets to sign into dapps and other web2 services will serve as a UX improvement for web3-natives. However, this leaves users open to correlation and tracking issues which became so detrimental in web2. Authentication via Peer DIDs or self-certifying identifiers could serve as an alternative solution here.
Unlike “vanilla” DIDs described above, Peer DIDs are designed to be used between 2 or N known parties. They can be used as a unique identifier for each service and/or interaction. Crypto wallet addresses within that digital identity can be stored with VCs as proof of verification at each merchant or service interaction.
Authorization & Access Control
While authentication confirms a user’s identity, authorization determines which resources an entity should be able to access, and what they are allowed to do with those resources. The two are separate processes but often go hand in hand in a UX flow. After signing in (authenticating) with social login to a third party service, users may be prompted with authorization requests like:
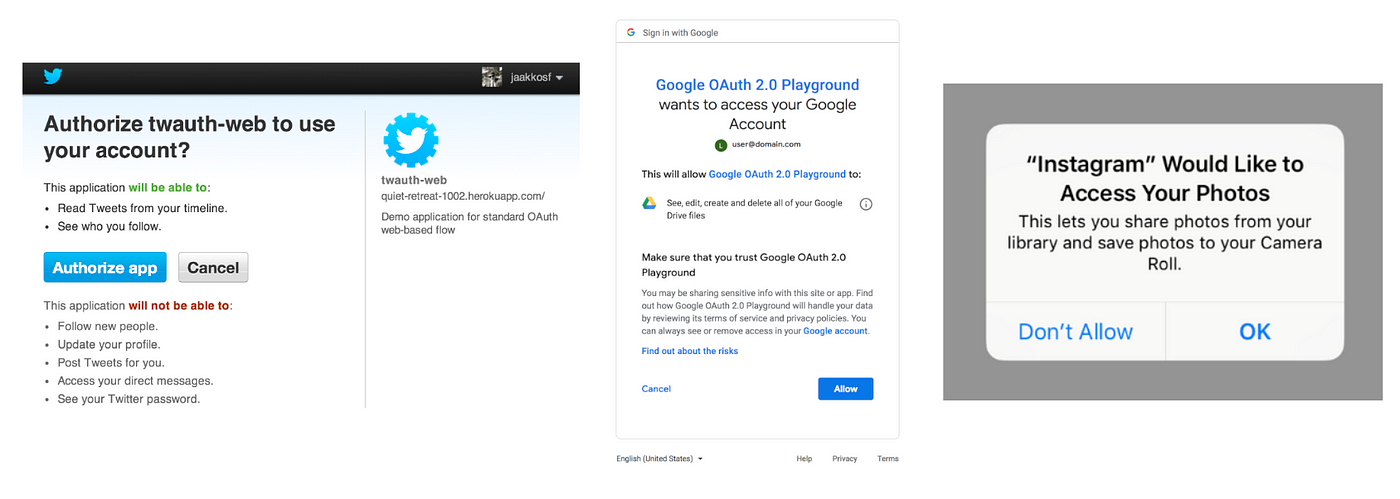
In the federated identity paradigm, the you are authorizing third party apps to view or update your data stored with identity providers like Google, who maintain the list of apps and associated permissions that you have authorized to those apps. Web3 authorization infrastructure and standards help achieve the same goal, except here you have self-sovereign data and can grant the right to each third party to decrypt/read/update it without centralized middlemen.
With the rise of tokenized communities came web3 token-gating products like Collab.Land, Guild, and Tokenproof. A primary use for these tools has been for access control to members-only Discord channels and more granular access based on roles and reputation. Instead of doling out access manually, communities can programmatically grant access based on token holdings, on-chain activities, or social verification.
Lit* is a decentralized key management and access control protocol which leverages MPC technology to distribute “shares” of a private key amongst Lit network nodes. Public/private key pairs are represented by a PKP (Programmable Key Pair) NFT, whose owner is the sole controller of the key pair. The PKP owner can then trigger the network to aggregate the key shares to decrypt a file or sign messages on their behalf when arbitrarily defined conditions are met.
In the context of access control, Lit enables users to define on-chain conditions that give access to off-chain resources. For example, a DAO can upload a file to Arweave or AWS, encrypt it with Lit, and define a set of conditions (e.g. NFT ownership). Eligible wallets sign and broadcast a message to protocol nodes which checks the blockchain to ensure the signer meets the conditions, and aggregates the key shares for the signer to decrypt the file if so. This same infrastructure can be used to unlock web2 experiences like Shopify discounts, token-gated Zoom rooms and Gathertown spaces, livestreams, and Google Drive access.
Kepler organizes data around user-controlled data vaults (“Orbits”) which represent a list of designated hosts for the data as a smart contract that only their keys can control. These data vaults can be governed by trusted parties, consensus mechanisms across hosts, resource owners, and permissioning validity. Anyone using SIWE can immediately utilize a private data vault to store their preferences, digital credentials, and private files. With “Bring your own storage” support for multiple storage backends, users can self-host or use hosted versions.
Some examples of how applications can use a combination of the building blocks previously mentioned:
- Orbis is a social networking app (“web3 Twitter/Discord”) that uses Ceramic for data storage and updates, DMs are encrypted via Lit first before being stored
- Use Lit as a decentralized encryption system to delegate who is able to decrypt your Tableland data
- Kepler can use Ceramic Documents as a beacon to route to private storage
- Create Lit PKPs that “owns” a Ceramic stream for an application, and grant Lit Actions (code on IPFS) the ability to sign and update the database if arbitrary conditions are met
CACAO is a standard to represent a chain-agnostic Object Capability (OCAP), created using Sign-in-With X. It defines a way to record the result of SIWx signing operation as an IPLD-based object capability (OCAP), creating not just an event receipt of an authentication, but also a composable and replay-able authorization receipt for verifiable authorizations.
Authorization methods let users grant apps the granular, well-scoped, and verifiable ability to view/update their data. Further, it can be session-based such that they don’t have to sign messages with every update, but instead have rich interactions on the app and sign once at the end of the session.
Attestations & Credentials
Here we reach the top of the decentralized identity infrastructure stack as represented here
Some terminology:
- Attestations certify that a claim and signatures are valid, they were born from the need for independent verification of recorded events.
- Credentials are any document detailing a piece of information about an entity, written and signed by another entity or themselves. Credentials are tamper-proof and cryptographically verifiable. These can be stored in a wallet.
Verifiable Credential (VC) is standard data model and representation format for cryptographically-verifiable digital credentials as defined by the W3C Verifiable Credentials specification:
- Issuers are the issuing parties of a credential (e.g. university)
- Holders own the credential (e.g. student)
- Verifiers verify the credential (e.g. potential employer)
- Verifiable Presentations is where users share their data with third parties who can verify that the credential has indeed been signed by the issuing party
Note that the terms “Issuer”, “Holder” and “Verifier” are relative here. Everyone has their own DID and their collection of credentials.
Credentials are the building blocks for reputation, which is a social phenomena that varies with context. One or a combination of credentials can be used as a proxy for an entity’s qualification, competence, or authority. Anyone could issue a claim to themselves that they graduated magna cum laude from a prestigious university, but that wouldn’t mean much to other people. It’s the university that holds the credentials recognized as legitimate or prestigious.
Although web3-native badging and proof-of-X projects don’t all adhere to W3C VC standards, we can draw parallels to the system described above.
- The most straightforward example are non-transferrable NFT badges that are only mintable by wallets that have completed some on-chain activity. Because all transaction history is on-chain, it’s verifiable and tamper-proof out the gate. DegenScore quantifies your ape-ishness by aggregating your interactions with DeFi protocols and outputs a score using rules written on a smart contract. You can mint this and treat it as a “DeFi Credential” held in your crypto wallet. If there was a Degen DAO restricted to those with a certain score, you can present this NFT to the DAO, a token-gating protocol can verify that you hold it, and in you go — Proof of Degen
- POAPs* attest you attended a certain event or met someone IRL— Proof of Attendance / Proof of Encounter
- Otterspace allow DAOs to decide what constitutes as meaningful work and issue its members an ntNFT badge for it, Proved requires a DAO to “sign off” on a claim before enabling its members to mint DAO-specific NFT badges for it — Proof of Contribution
- 101 issues ntNFTs once a student passes a test at the end of its online courses — Proof of Learning
- Kleoverse issues users Typescript, Rust, or Solidity competency badges based on Github data — Proof of Skill
In addition to the access control use case outlined above, Lit PKPs could also behave as a cryptographic notary by which Lit Actions perform checks before signing off on a credential. For example, a decentralized education platform can allow course creators to define what constitutes as passing a test, deploy these conditions as a Lit Action, and programmatically issue VCs based on those conditions using its PKP.
2 questions arise here: which of these credentialing data points are meaningful and how do we aggregate them for reputation?
Orange Protocol offers one solution to this: consolidate these data points into well-defined schemas through Model Providers. On Orange, MPs are generally platforms that have measures for reputation assessment within their systems. “Data Providers” allow their data to be used as input for models designed by Model Providers. MPs then add a method of calculation and assignment of reputation markers to different entities, and make these Models available for others to use. Dapps can curate and plug in these reputation models for their use case.
So far Aave, Gitcoin, Snapshot, DAOHaus and more have provisioned their data into Orange. This data was modeled by them and other projects such as Dework, talentDAO, and Crypto Sapiens to provide members with ntNFTs, which unlock a wide spectrum of opportunities from improved Discord permissioning using CollabLand and Guild through to reputation-weighted governance on Snapshot.
Privacy
No discussion on identity infrastructure is complete without privacy considerations and the technological primitives that enable it. Privacy is a factor at all layers of the stack. Blockchain adoption over the past decade has accelerated R&D of powerful cryptographic primitives like zk-proofs, which in addition to its applications in scaling technologies like rollups, allow identities to make nuanced, privacy-preserving statements about publicly verifiable information.
Privacy guarantees help us avoid the negative externalities that come from producing credible claims using completely transparent data. Without these guarantees, third parties could initiate out-of-scope interactions unrelated to the original transaction (e.g. advertising, harassment). Using cryptography and zk tech, we can architect identity systems in which interactions and data-sharing are “sandboxed” within well-defined, context-relevant scopes.
“Vanilla” Verifiable Credentials often come in the JSON-JWT or JSON-LD format, each with external or embedded proofs (digital signatures) that render them tamper-proof and verifiable as authored by the Issuer.
Zk-proofs and novel signature schemes enhance W3C VCs with privacy-preserving properties like:
- Anti-Correlation. Every time a holder shares a credential, this identifier is shared and thus, each presentation of the credential means that it is possible for verifiers to collude to see where the holder presented their credential and triangulate it to an identified person. With signature blinding, you can share a unique proof of the signature each time without sharing the signature itself.
- Selective Disclosure. Share only necessary attributes from the VC and hide the rest. Both JSON-JWT credentials and JSON-LD LD-Signature credentials require that the holder share the whole credential with verifiers — there is no “partial” share.
- Compound Proofs: Combine attributes from multiple VCs into one proof without going to the issuer or generate a new VC.
- Predicates. Allow hidden values to be used in operations with a value provided by the verifier. For example, prove that the holder’s account balance is above a certain threshold without revealing the balance, or the often-cited scenario of proving you’re of legal drinking age without revealing your birthdate.
One promising approach is the BBS Signature scheme, originally proposed by MATTR in 2020. The proposal allows BBS signatures to be usable with the JSON-LD format commonly used by VCs. The holder can selectively disclose statements from the originally signed credential. The proofs generated by the scheme are zero-knowledge proofs of the signature, meaning a verifier is unable to determine which signature was used to generate the proof, removing a common source of correlation.
Iden3 is a zk-native identity protocol which offers a programmable zk framework and open-source libraries for zk-identity primitives, authentication, and proof generation for claims. The protocol generates keypairs for each identity using the Baby Jubjub elliptic curve, which is designed to work efficiently with zk-SNARKs used to prove identity ownership and claims in a privacy-preserving manner. PolygonID currently leverages the protocol for their identity wallet.
Applied zkp is an active area of research and experimentation that has built a lot of excitement from the crypto community over the past few years. In web3, we are already seeing it being put to use in applications like:
- Private airdrops: Stealthdrop
- Privacy-preserving but credible attestations: Sismo (ownership), Semaphore (membership)
- Anonymous messaging: heyanon
- Anonymous Polling/Voting: Melo
Conclusion
Some general takeaways from this research.
- Just like how crypto catalyzed DPKI development and adoption, composable reputation which grants online/IRL access privileges will be the catalyst for decentralized identity infrastructure. Credential issuance (proof-of-x) protocols are fractured right now across use cases and blockchain networks. In 2023 we will see the aggregation layer for these (e.g. profiles) mature and gain adoption as a unifying interface, especially if it can be used to unlock experiences beyond crypto, such as access to events or e-commerce discounts.
- Key management remains a friction point that is vulnerable to single points of failure. A clunky experience for most cryptonatives, and downright inaccessible for most consumers. Federated identity was a UX improvement to the web 1.0 paradigm, allowing single sign-on vs usernames and passwords for each application. Though web3 authentication UX is improving, it still offers inferior UX requiring seed phrases and offers limited recourse if keys are lost. We will see an improvement here as things like MPC technology matures and gains traction amongst individuals and institutions.
- Cryptonative infrastructure are meeting users where they are in web2. Web3 primitives are starting to integrate with web2 applications and services, to bring decentralized identity to the masses e.g. Collab.Land integration with Nuggets to allow Reddit users to mint their reputation as a VC to unlock access. Auth0 authentication & authorization middleware integrated SIWE as an identity provider, their base of 2k enterprise customers can now offer wallet sign-on in addition to SSO.
- Curation mechanics need to be proven out as data becomes democratized. Like how indexing protocol The Graph uses a network of curators and delegators to signal on the most useful subgraphs (APIs for on-chain data), data models around user and reputation on protocols like Ceramic and Orange will take time and community participation to mature beyond DAOs and cryptonative use cases.
- Privacy considerations. Projects should carefully consider the implications of public or permanent storage when selecting their stack. “Pure” public-data ntNFTs will likely be appropriate for a limited set of use cases (e.g. an abstraction for some on-chain activity) relative to the combination of privacy-preserving VCs, ephemeral and Peer DIDs, and ZKPs of on/off-chain activity which offer features like selective disclosure, key rotation, anti-correlation, and revocability.
- New cryptographic tools like zkSNARKs will be a crucial building block for next-gen identity infrastructure. While ZKPs are currently being applied to isolated use cases, it will take a bottoms-up, collective R&D effort to converge on application design patterns, implementation of ZK circuits for cryptographic primitives, circuit security tools, and developer tools. This is something to follow closely.
Decentralized identity is a megaproject that is much bigger than one team. It takes an ecosystem-wide effort to converge on standards, iterate on primitives, and check one another on the implications of design decisions.
This covers the infrastructure portion of the decentralized identity stack, the next one will address profiles, sybil-resistance, compliance, and the application layer which are made possible by the building blocks mentioned here.
If you are building in this realm or have additional thoughts on the topic, would love to hear from you.